ESD#4 has been around for some time. I did not start testing the conditions I am pushing the ASE into with this EBF for several reasons. But now it seems to really be a pity I haven’t done so from the start. After making a few tests with ESD#2 on Solaris x64, and after making similar tests with ESD#3 on Solaris SPARC I decided to move on. The reason for this is that I was not really satisfied with what I saw. True, I am pushing the ASE into an area which is very imcomfortable for it (simulating a situation which a highly respected Sybase engineer has called running a “really bad code”). But this is a real-client situation and I must know how my ASE will handle it. It is really naive to think that ASE should handle only properly formed workload written by developer teams sensitive to the way DB operates. Today more and more code is written which care very little for DB needs. Either we face it or the customers moves to DBMS systems that cope with “bad code” better than ASE…
So, on the one hand, I was not satisfied with the results of my tests – especially with high spinlock contention for various spinlocks guarding the procedure / statement cache. On the other, ESD#4 (and the weird fish ESD#3.1, which has only a little portion of fixes out of ESD#4, but came later on – a couple of days ago in fact) says to have worked on the procedure cache spinlock contention a little more. Since this is what I was after, I switched the direction a bit.
Unfortunately, I could not spend much time on the current tests, and I will not be able to spend any more time on them in days to come (customer calls). I did succeed, though, to do some initial tests which I would like to share. Especially since there is a parallel discussion on ISUG SIG area (now restricted to paid members only) which mentions statement cache issues. Lovely discussion, but it really deals with how to tune the ASE to handle “good code” without waste of resources and how to monitor the waste. It still avoids the situation when the ASE is bombarded with “bad code.”
An aside installation note on ESD#4. I had to truss the installation process since it has been constantly hanging. As it turned out, the space requirement which the installation checks does not take into account available swap space. Installer uses /tmp quite freely, and my 800MB of /tmp was not enough for the installation of this ESD. Had the installation informed me on this requirement in time, it might have saved me some time and pain. I hope the good code that manages the installation will be made even better in future…
So here are the settings:
| ESD#2 | 09:30 | 09:35 | 09:40 | 09:43 | 09:45 | 09:50 | 09:55 | 10:00 | 10:03 |
| STREAM | 0 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 1 |
| PLAN SH | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 |
| STCACHE(J) | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 |
| DYNPREP(J) | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| STCACHE(MB) | 0 | 0 | 0 | 20 | 20 | 20 | 20 | 20 | 20 |
| ESD#2 | 10:06 | 10:12 | 10:15 | 10:20 | 10:23 | 10:25 | 10:28 | 10:30 | |
| STREAM | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | |
| PLAN SH | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | |
| STCACHE(J) | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | |
| DYNPREP(J) | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | |
| STCACHE(MB) | 100 | 100 | 100 | 100 | 100 | 100 | 20 | 100 | |
| ESD#4 | 12:56 | 12:58 | 12:59 | 13:01 | 13:02 | 13:03 | 13:04 | 13:06 | 13:07 |
| STREAM | 0 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 |
| PLAN SH | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 |
| STCACHE(J) | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 |
| DYNPREP(J) | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| STCACHE(MB) | 0 | 0 | 0 | 20 | 20 | 20 | 20 | 100 | 100 |
| ESD#4 | 13:08 | 13:10 | 13:11 | 13:12 | 13:14 | ||||
| STREAM | 0 | 0 | 1 | 1 | 1 | ||||
| PLAN SH | 0 | 0 | 0 | 1 | 1 | ||||
| STCACHE(J) | 1 | 1 | 1 | 1 | 1 | ||||
| DYNPREP(J) | 0 | 0 | 0 | 0 | 0 | ||||
| STCACHE(MB) | 100 | 100 | 100 | 100 | 20 |
Really what it says is that we are playing with 3 DB and 2 JDBC client options. On the DB side we are playing with streamlined dynamic SQL, plan sharing and statement cache size. On the JDBC client side we are playing with DYNAMIC_PREPARED and set statement_cache on setting (the last is not really on JDBC side, but addresses the needs of that client). Our aim: to keep ASE from crumbling beneath the bad code, which in the time before statement cache refinements was manageable.
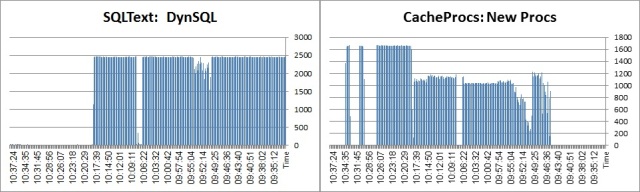
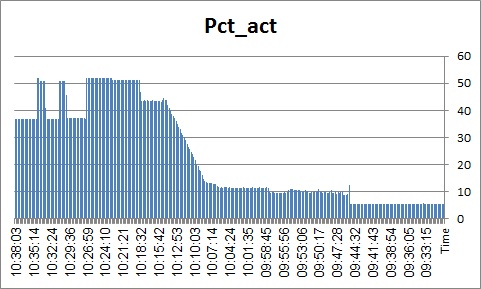
We start with ESD#2

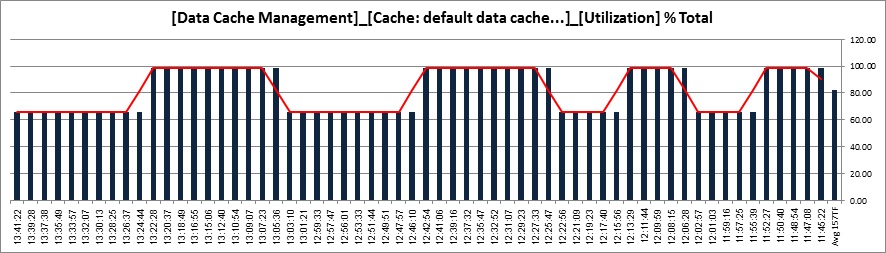
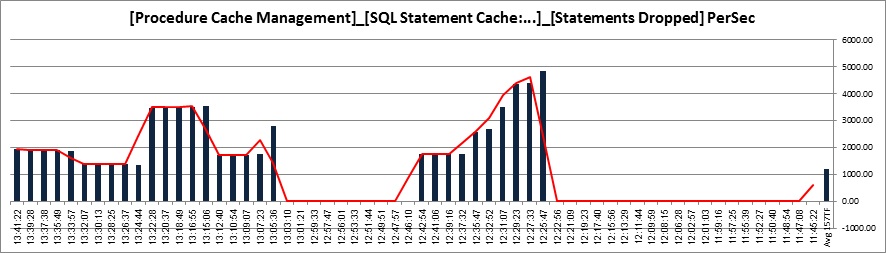
Statement Cache situation:

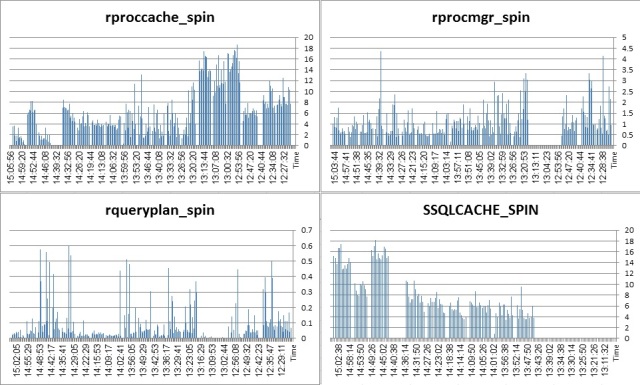
Spinlock situation:

The rate of LWP/Dynamic SQLs creation:
monitorconfig:
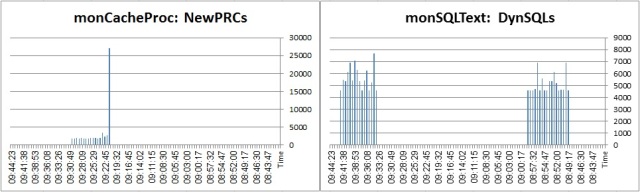
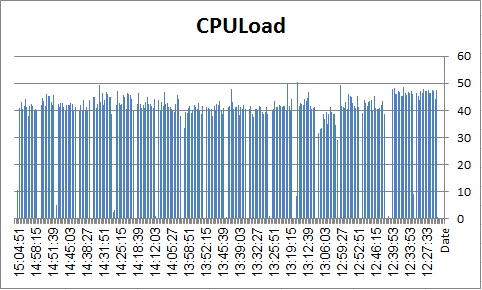
Now ESD#4:

Statemet Cache situation:

Spinlock Situation:

The rate of LWPs/Dynamic SQL creation:

monitorconfig

Before anything else, I must add a short note about reducing the size of statement cache. Although the configuration parameter is dynamic, both in ESD#2 and ESD#4 there is a real problem reducing its size. After the statement cache has been utilized (100 MB in my tests), when the statement cache is reduced to a lower value (20 MB or even 0 MB) the memory is not released. This causes a sensible spike in CPU utilization and a large SSQLCACHE spinlock contention seen on the graphs above. Probably a bug. This is what prsqlcache reports:
1> sp_configure “statement cache”, 0
2> go
Parameter Name Default Memory Used Config Value Run Value Unit Type
———— ——————– ———– ——————– ——————– ——————– ——————–
statement cache size 0 0 0 0 memory pages(2k) dynamic
(1 row affected)
Configuration option changed. ASE need not be rebooted since the option is dynamic.
Changing the value of ‘statement cache size’ does not increase the amount of memory Adaptive Server uses.
(return status = 0)
1> dbcc prsqlcache
2> go
Start of SSQL Hash Table at 0xfffffd7f4890e050
Memory configured: 0 2k pages Memory used: 35635 2k pages
End of SSQL Hash Table
DBCC execution completed. If DBCC printed error messages, contact a user with System Administrator (SA) role.
1>
Now to the rest of the findings. It seems that ESD#4 treats the situation of a client code wasting its statement (and procedure) cache memory structures – uselessly turning over the pages chain – much better. I did not post the data from my tests on a large SPARC host as promised earlier since they were not really better. With this new information, I will have to rerun the tests next Sunday on the ESD#4, SPARC. Hopefully, I will get a much improved performance metrics there as well. I am eager to see the statement cache/procedure cache saga in ASE 15.x to be laid to rest. It has really been a pain in the neck dealing with this stuff. I hope that at last we may sigh a relief… and get back to the optimizer issues….
Next update will probably come on Monday, unless something interesting is discovered before that (and I have time to test and testify on it here).
Yours.
ATM.






















































 Note: DBCC PSS is not a formally documented command; it's output may change between versions without warning. This example output is from Adaptive Server Enterprise/15.7.0/EBF 20369 SMP ESD#02 /P/Sun_svr4/OS 5.10/ase157esd2/3109/64-bit/FBO/Sat Jul 7 10:07:17 2012
Note: DBCC PSS is not a formally documented command; it's output may change between versions without warning. This example output is from Adaptive Server Enterprise/15.7.0/EBF 20369 SMP ESD#02 /P/Sun_svr4/OS 5.10/ase157esd2/3109/64-bit/FBO/Sat Jul 7 10:07:17 2012 .
.


